
お茶情の研究を覗いてみよう
このシリーズでは、情報科学科の学生が行った最先端の研究から、
国際学会で高い評価を得たものを紹介していきます。
第3弾:異常事態発生!
紹介論文
シリーズ第3弾で紹介する研究は、丸千尋さんが博士課程在学中に行った以下の研究です。
Chihiro Maru, Boris Brandherm, and Ichiro Kobayashi “Combining Transformer with a Discriminator for Anomaly Detection in Multivariate Time Series,” 2022 年 12 月にソフトコンピューティングと先進的なインテリジェントシステムに関する国際会議 SCIS&ISIS 2022 (http://soft-cr.org/scis/2022/index.html) にて発表、採択された 234 件の論文の中から最も優れた論文 1 件のみに送られる最優秀論文賞 (The Best Paper Award)(https://www.ocha.ac.jp/news/d011589.html )を受賞。(丸さんが大学院博士課程に在学中のとき。)
概要と背景
コンピュータが日常生活の隅々まで行き渡った現代、私たちの生活は大量のデータに囲まれています。気象観測データや株の取引記録といったものから、スマートウォッチによる体のデータなど日々、多くのデータが蓄積されています。さらに、twitter へのつぶやきやブログ、インスタグラムなど、情報発信や自己表現のデータも増え続ける一方です。
これらのデータの中には多くの役に立つ情報が含まれています。しかし、それらを上手に取り出すのは簡単なことではありません。今回、紹介する研究は、このような大量のデータの中から異常事態を検知する技術です。
異常の検知はさまざまな場面で役に立ちます。例えば、気象観測をする機械が気温 100 度を観測したとすれば、それは何か異常なこと、例えば機械の故障や観測所の火事などを示しているに違いありません。株価の異常な動きは犯罪が絡んでいる可能性を示唆しますし、スマートウォッチが心拍リズムの異常を検知したら、それは人命に関わるでしょう。
これらの異常は、専門家がデータを見れば発見することができます。しかし、世の中にあふれる大量のデータをすべて専門家がチェックするのは現実的ではありません。そこで必要になってくるのが、これら異常な事態を自動で検知する技術です。丸さんが取り組んだのはこのような研究です。
研究の始まり
丸さんが異常事態の発見に興味を持ったのは、学部時代、コンピュータネットワークを専門とする小口研究室に所属していたときのことです。私たちの生活は、もはやネットワークなしには成り立たなくなっています。これは、大規模災害が起きてネットワークが遮断されると私たちの生活に甚大な影響を及ぼすことを意味しています。では、ネットワークの遮断はどのようにしたら見つけられるでしょうか。ネットワークがつながっていれば、それを使って調査できそうですが、ネットワークが遮断してしまっていたら手も足も出ません。
そこで、丸さんは大規模災害が起きたときの twitter への投稿に着目しました。大規模災害が起きると、多くの人がスマホを使って普段とは異なる大量の情報を発信します。特に、ネットワークが機能していないといった情報も流れます。物理的なネットワークが遮断されても、スマホを使った無線通信が生きていれば、これらの情報は外に出てきます。このような普段とは違う状況を見つけ、そこから重要な情報を抽出することでネットワークの遮断を見つけようということです。
その後、大学院の修士課程に進んだ丸さんはこの研究をさらに続け、twitter など SNS から適切に情報を抽出すれば、大規模災害時にネットワークが遮断しても、それを検知できることを示しました。この成果は、国際会議で発表し、Young Author Recognition という賞を受賞しています。(https://www.ocha.ac.jp/news/h280113_2.html)
「異常」とは?
修士課程で行った研究は、大量に流れてくる SNS の情報から、例えば「ネットワークにつながらない」といった言葉を探すことで、ネットワークの遮断を検知するものでした。このような特定の言葉を探す方法は、探すべき言葉がわかっている場合にはうまく働きます。しかし、増え続ける様々な種類のデータすべてについて、探すべき適切な言葉を見つけてくるのは次第に現実的ではなくなってきます。さらに、テキストではなく数値から情報を抽出する場合には別の問題 も出てきます。
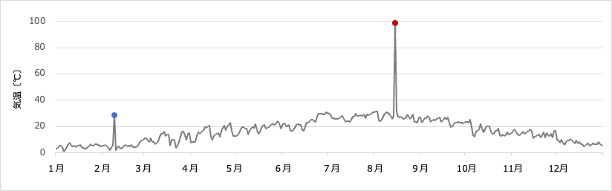
再び気温の例を考えてみましょう。図 1 は 1 年の気温推移の例をグラフにしたものです。このような数値のデータの中から赤の点が異常であることを検知したかったら、例えば気温が 60 度を超えたら異常と判断すれば良さそうです。これは、テキストデータから特定の条件を満たす文字列を探すのと同じ考え方です。しかし、数値データの場合はテキストデータの場合には考えなくてもよかった異常の「程度」を考えなくてはいけなくなります。
気温が 100 度であればすぐに異常とわかります。では 50 度だったらどうでしょうか。日本の気温であれば異常ですが、赤道付近であれば 50 度はあり得るかも知れません。40 度ならどうでしょうか。最近の異常気象では、日本でも 40 度が観測され始めています。このように数値データでは「何を満たしたら異常か」を判断するのは難しくなります。
問題をさらに複雑にしているのは、異常の判断が数値ひとつでできるとは限らないところです。図 1 にはもうひとつ異常な点、青の点があります。青の点は、気温としては 30 度なのでそれだけでは異常とは判断できません。しかし、その気温が真冬の 2 月に観測されたとなれば、それは異常でしょう。言い換えると、青の点を異常と判断するためには、30 度という数値だけでは無理で、「2 月に 30 度」というふたつのデータが必要なのです。このように複数の値からなるデータ のことを多次元データと呼びます。多次元データの異常を判断するには、たくさんのデータを一度に見なくてはならず、異常の判定基準を作るのはずっと難しくなります。
判定基準を簡単には作れないとなると、どのようにして赤の点や青の点が異常であることを判定したら良いでしょうか。そのヒントは、私たちが普段どのように異常を判定しているのかにあります。私たちは、図 1 を見たとき、たとえこれが気温のデータであることを知らされなかったとしても、赤の点や青の点が異常であることはすぐにわかります。その際、赤の点が具体的に何 度以上だから異常などと判断しているわけではなく、周りの状況を見て総合的に異常を判断しています。これと同じことをすれば、異常の判定基準を定めることなく、またどのようなデータに対しても異常を判断できそうです。
深層学習の利用
「周りの状況を見て総合的に異常を判断する」というのは、このシリーズ第2弾「この単語、難しい?」 でも出てきた深層学習の匂いがします。つまり、たくさんの状況をコンピュータに学習させておけば、異常が起きたときにコンピュータが知らせてくれるのではないかということです。修士課程を修了後、丸さんは異常検知の研究をさらに発展させるため、人工知能を専門とする小林研究室に移って、深層学習を使った異常検知の研究に取り組みました。
しかし、ここで問題が生じます。深層学習というのは、例えば大量の犬の画像と猫の画像を与えて学習すると、犬か猫かの判定ができるようになるというイメージです。大量のお手本があれば、そのお手本の特徴をとらえて判別ができるようになります。ですが、丸さんが検知したいものは異常なデータです。異常ではない普通のデータなら大量にありますが、異常なデータというのはごくたまにしか現れません。普通のデータの特徴は簡単に学習させられますが、異常なデータはほとんど学習させることができないのです。
ごくたまにしか現れない異常なデータを検出するため、丸さんは深層学習の手法の中からふたつの手法を組み合わせることにしました。ひとつは、エンコーダ・デコーダモデル、もうひとつは敵対的生成ネットワークです。
エンコーダ・デコーダモデル
エンコーダ・デコーダモデルというのは、機械翻訳などの分野で使われる技術です。機械翻訳では、例えば日本語の文を与えると、それが英語に翻訳されたりします。その仕組みは、大雑把には図 2 のようになっています。
まず、入力の日本語の文をエンコーダに渡します。エンコーダというのは、入力文の特徴をとらえて、それを何らかのデータに符号化(エンコード)するものです。符号化されたデータは、その文の本質(意味といっても良い)を表していると考えて構いません。一度、入力文の本質をとらえられるようになると、それを色々な言語に変換できるようになります。デコーダは、そのようにして得られた本質のデータを受け取ると、それを分解(デコード)して対応する英語の文を出力します。

このようなことを実現するエンコーダ・デコーダを作るためには、いろいろな入力文をエンコーダに与えて、デコーダが対応する出力文を出せるようにパラメータを調整(学習)していきます。この処理を大量の入力文・出力文に対して行うと、次第にエンコーダとデコーダの間の部分に入力文の本質(意味)が現れるようになるのです。これを異常検出に用いる際には、入力文として正常なデータを、出力文としては入力文と同じデータを与えて学習させます。入力文として異常なデータではなく正常なデータを与えるのは、異常なデータはほとんど手に入らないからです。では、出力文として入力文と同じデータを与えるのはなぜでしょうか。機械翻訳の場合は、入力文と出力文は日本語の文と英語の文というように別の言語を与えていました。それを、どちらも日本語の文にするのです。
入力文と出力文を同じにしてしまっては、得られる出力文は初めからわかっているのでエンコーダとデコーダに通す意味はないと思うかも知れませんが、そうではありません。エンコーダとデコーダに通すと、その間の部分に普通のデータの本質が何かを学習できるのです。ここで、学習したのは普通のデータのみであって、異常なデータは学習していないことに気をつけてください。普通のデータは学習しているので、エンコーダ・デコーダに通すともとのデータがそのまま返ってきます。しかし、ここに学習していない異常なデータが入ってくると、どのように処理して良いのかわからず、入力とは異なるデータが出力されるようになるのです。このふたつを区別できれば、普通のデータと異常なデータを区別できるだろうということです。
以上がエンコーダ・デコーダを使った異常検知の原理ですが、実はこの方法をそのまま行ってもあまり良い結果は得られません。ある程度の異常検知はできますが精度が良くないのです。普通のデータの特徴は学習できているので、普通のデータを入力すると確かに同じデータが出力に現れます。しかし、学習していない異常なデータであってもエンコーダ・デコーダがたまたまうまく動いてしまって、入力と同じではないにしろ、似たような出力が得られてしまうのです。
普通のデータと異常なデータをよりはっきり区別するため、丸さんはふたつ目の手法を導入しました。それが敵対的生成ネットワークです。
敵対的生成ネットワーク
敵対的生成ネットワークというのは、ふたつのニューラルネットワークを用意し、それぞれを競わせる形で学習させる手法です(図 3)。ふたつのニューラルネットワークはそれぞれ生成ネットワーク、識別ネットワークと呼ばれます。生成ネットワークは、なるべく普通らしくみえるデータを生成できるように学習します。例えば気温のデータなら「2 月、3 度」「7 月、28 度」などなるべく「本物っぽいデータ」を作り上げられるように学習します。一方、識別ネットワークは、与えられたデータが「本物」か生成ネットワークが生成した「作り物」かを判定できるように学習します。このふたつのネットワークを競わせる形で学習させると、生成ネットワークは普通のデータの特徴をとらえてより本物っぽいデータを生成するようになり、識別ネットワークも本物のデータの特徴をとらえてより正確な判定をできるようになります。これを異常検知に用いようというわけです。
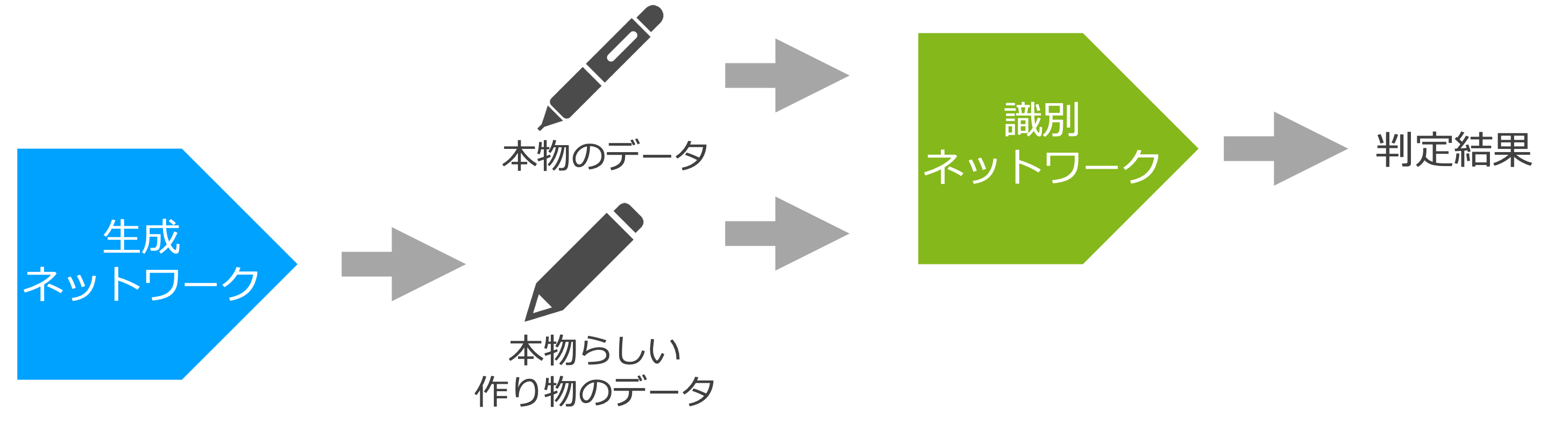
図 3 の敵対的生成ネットワークは、異常なデータのことについては考慮されていません。識別ネットワークに渡される「本物のデータ」というのは(本物の)異常ではないデータです。また、生成ネットワークが作るのも(本物ではありませんが)異常ではない普通のデータです。なので、識別ネットワークに異常なデータを渡したときにどのような判定結果を出すかはわかりません。図 3 をそのまま使うのでは異常検知を行うことはできないのです。
ここで図 3 を見返すと、生成ネットワークがエンコーダ・デコーダモデルのデコーダに近いことに気が付きます。生成ネットワークは(普通の)本物っぽいデータを作っているのに対して、デコーダも(エンコーダの入力と同じ普通の)データを作っています。異常検知を実現するポイントは、敵対的生成ネットワークの生成ネットワークを(エンコーダと)デコーダに置き換えるところにあります(図 4)。
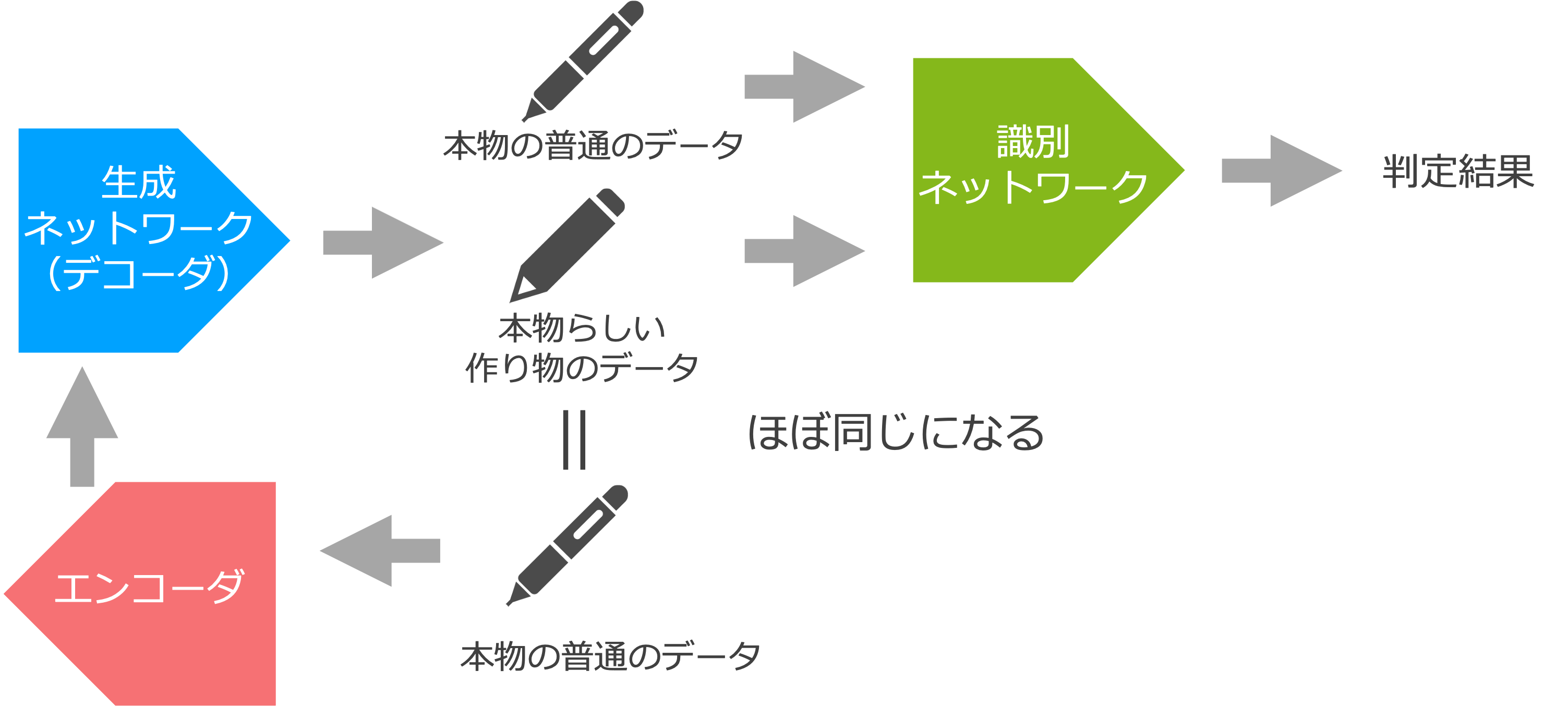
図 4 に出てくるエンコーダとデコーダは、これまで通り普通のデータを使って学習させます。ですが、これまでのように「エンコーダの入力とデコーダの出力がなるべく同じになる」ように学習するのではなく、「デコーダの出力がなるべく本物っぽくなる(識別ネットワークに「本物」と判定される)」ように学習します。ここが、これまでのエンコーダ・デコーダモデルと決定的に違うところです。
このように学習すると、普通のデータがエンコーダに入力されると、それと似たデータがデコーダから出力されます(図 4)。これは、入力の本物のデータと似たデータを出力すれば、識別ネットワークがそれを本物と判定する可能性が高いからです。一方、図 5 のようにエンコーダに異常なデータを渡すと、それは入力と似たデータではなく、本物らしいデータに変換されて出力されます。これは、入力の異常なデータと似たデータを出力したら、識別ネットワークに本物ではないと判定されてしまう可能性が高いからです。すると、エンコーダ・デコーダの入出力が似ているなら普通のデータ、大きく異なるなら異常なデータと判断できることになります。
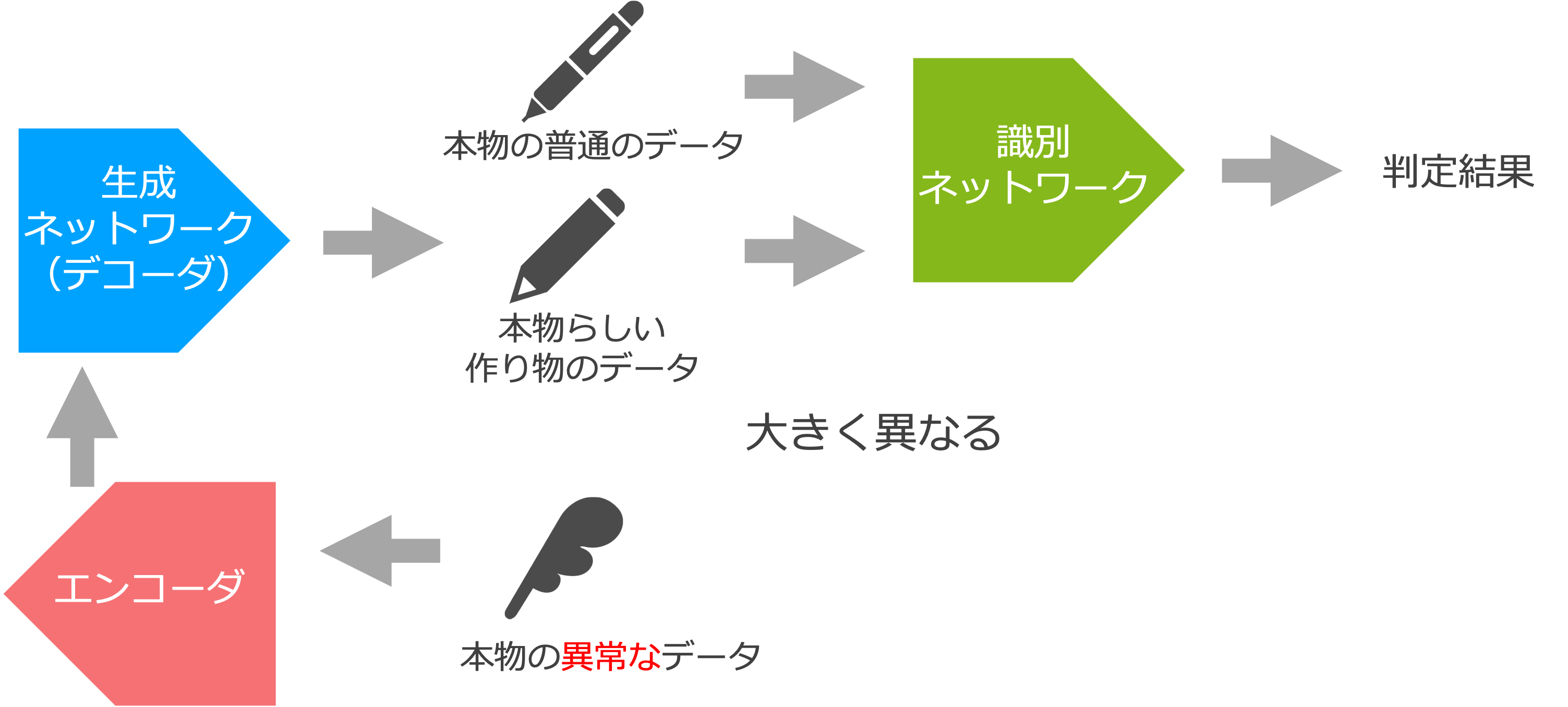
ここでのポイントは、エンコーダ・デコーダの学習も識別ネットワークの学習も普通のデータのみを使って行っているところです。異常なデータを使わなくても、「普通のデータ」はそのままで普通のデータであり「異常なデータ」はそのままでは普通のデータには見えないことを使うと両者を区別できるようになるのです。
時系列データの異常検知
エンコーダ・デコーダモデルと敵対的生成ネットワークを組み合わせると、異常なデータを学習しなくても異常なデータを検知できることがわかりました。丸さんは、これをさらに発展させて時系列データを扱えるようにしています。時系列データというのは、時間にそって得られるデー タのことです。例えば、図 6 は心電図の例です。
図 6 の心電図を見ると、心臓の動きに合わせて電圧が大きく変化していますが、途中でほとんど電圧の変化がないまま続いている部分があります。これは、何らかの異常を示していると考えられる部分です。ですが、その電圧自体は異常な値ではありません。実際、正常に心拍を刻んでいるときにもその電圧をとることはあります。また、気温のデータのように、心電図の情報を多次元にしたら異常と判断できるかというと、そうでもありません。特定の時間にその電圧をとっていたことが異常なのではなく、電圧が一定のまま続いているところが異常だからです。
![心電図の例。赤い部分で電圧の変化が少ないまま続いているのは異常。Keogh ら [1] のデー タから作成](image/heart.png)
Keogh ら [1] のデー タから作成
このように、ひとつのデータが異常なのではなく、時間的に関係のあるデータが全体として異常であることは、ここまでに述べてきた方法では検知できません。そのような異常も検知するため、丸さんは異常検知の仕組みをさらに改良しました。具体的には、エンコーダ・デコーダモデルをトランスフォーマと呼ばれる別のネットワークに置き換えます。
エンコーダ・デコーダモデル(の中でも回帰型ニューラルネットワークと言われるものを使ったモデル)は、連続して入ってくる入力を前から順番に処理するため、入力の前後の関係は上手にとらえることができます。例えば「これはペンです。」という入力があったとき、「これは」と「ペン」の間の関係、「ペン」と「です。」の間の関係は上手にとらえることができます。ところが 「これは」と「です。」のように単語の間が離れてくると次第にその間の関係を捉えるのは難しく なってきます。特に、心電図の例のように長く連続したデータの関係はとらえることができないのです。
トランスフォーマは、そこの部分を改良したモデルです。ある一定の幅の期間を設け、その間のデータすべてを考慮に入れて学習できるようなモデルです。その詳しい仕組みは省略しますが、 トランスフォーマを使うと心電図の異常など時系列データの異常も検知できるようになっていきます。
時系列を扱えるようになると、今度は誤差の問題が顕著になってきます。ひとつのデータを扱っていたときには、そのひとつのデータの誤差を気にしていればよかったのですが、時系列のデータを扱うと誤差が累積していきます。ひとつひとつは小さな誤差でも時間がたつうちに誤差が大きくなり、いずれ判定結果に影響を及ぼすようになってきます。これに対して、丸さんは結果に寄与しない小さな値を 0 とみなして無視することで、上手に誤差を抑え、より精度の高い異常検知をできるようにしています。
このように、正確な異常検知を行うためにはさまざまな技術と細かな調整が必要です。それらの集大成として多次元でなおかつ時系列のデータに対する異常検知が可能になっているのです。すでにスマートウォッチなどを使って体のさまざまな情報がどんどん蓄積されるようになっています。近い将来、そういったデータが全て自動で検査され、異常が起きたらすぐに知らせてくれるようになるかも知れませんね。
参考文献
[1] E. Keogh, J. Lin, and A. Fu, HOT SAX: Efficiently Finding the Most Unusual Time Series Subsequence, Fifth IEEE International Conference on Data Mining (ICDM’05), pp. 226-233 (2005)
バックナンバー
問い合わせ先
大学へのお問合せはこちらをご覧ください〒112-8610 東京都文京区大塚2-1-1
TEL : 03-5978-5704
FAX : 03-5978-5705
責任者 : 情報科学科HP運営委員会 伊藤貴之

※このウェブサイトは情報科学科の学生によって制作されています。