
お茶情の研究を覗いてみよう
このシリーズでは、情報科学科の学生が行った最先端の研究から、
国際学会で高い評価を得たものを紹介していきます。
第2弾:この単語、難しい?
紹介論文
シリーズ第2弾で紹介する研究は、田屋侑希さんが修士1年のときに行った以下の研究です。
Yuki Taya, Lis Kanashiro Pereira, Fei Cheng, and Ichiro Kobayashi ''OCHADAI-KYOTO at SemEval-2021 Task 1: Enhancing Model Generalization and Robustness for Lexical Complexity Prediction,'' 2021 年 8 月に自然言語分野における最高峰の国際会議に併設して開かれた意味評価に関する国際ワークショップ SemEval 2021 (https://semeval.github.io/SemEval2021/) にて発表し、奨励賞 (Honarable mention) (https://www.ocha.ac.jp/news/20210817.html)を受賞。(田屋さんが大学院修士2年のとき。)
概要と背景
田屋さんがこの研究を行ったのは、これまで行っていた研究が一区切りつき、次の研究の方向性を探っていたときです。すでに自然言語処理や人工知能を専門とする小林研究室で、深層学習を使って一定の成果をあげていましたが、新しいテーマの研究を行うにあたり、身につけた技術をさらに磨こうと考えていたところ、ちょうど国際的なコンテストが開かれることを知りました。それが、今回、受賞につながった国際ワークショップ SemEval 2021 です。
このワークショップは毎年、自然言語処理に関するいろいろな難しい問題を掲げ、皆で競い合って解くことにより、自然言語処理技術の向上をはかっています。田屋さんは、その中から「単語の難しさ」を予測する問題に取り組みました。これは、深層学習の最新の手法などを試して、自分の技術を磨く良い機会だと考えたからです。
私たちは文章を読むとき、その中に現れる単語の意味から、全体の意味を理解していきます。使われている単語がわかりやすければ、全体の意味を取るのも簡単ですが、難しい単語が出てくると、うわ困ったな、と思いつつ、文脈から意味を想像することになるでしょう。どうしても想像できなかったら辞書を引くことになります。
では、文が与えられたとき、その中の単語の「難しさ」、つまり比較的わかりやすい単語なのか、難しめの単語なのかを自動で判定することはできるでしょうか。これが田屋さんの取り組んだコンテスト問題です。
単語の難しさを自動で判定できると、いろいろなところで役に立ちます。例えば、子供向けの本を書いているとしましょう。その中で使っている難しい単語を自動的に指摘してくれれば、それをより簡単な単語で言い換えたり、注釈をつけたりすることができます。また、外国の人向けの文章を書く際にも、簡単な単語を使ってわかりやすく書くのは重要でしょう。
では、単語の「難しさ」を自動で判定するにはどうすればよいでしょうか。
「難しさ」の指標
このような問題をコンピュータを使って解く標準的な方法は、世の中にある単語すべてについて、あらかじめ「難しさ」を表す数値を割り振っておく方法です。単語の難しさを 0 から 1 までの数字で表現することにしましょう。例えば「甘い」という単語の意味はすぐにわかるので 0.2 など小さめの数字を割り振り、「意味」など少し抽象的で難しい単語には 0.7 など大きめの数字を割り振ります。世の中にはたくさんの単語がありますので、それらすべてについて数字を振るのは簡単ではありません。でも、コンピュータを使って何らかの基準で難しさを割り振ることができれば、難しさの指針が得られそうです。
しかし、この手法には少なくともふたつの問題点があります。ひとつは、世の中にたくさんある単語にどういう基準で難しさを割り振るのかという問題です。「難しさ」は人によって感じ方の異なる主観的な指標です。多くの人に納得してもらえるような数値を割り振るのは簡単ではなさそうです。
さらに深刻なのは、単語の難しさは文脈によって異なるという問題です。上にあげた「甘い」という単語は「甘いお菓子を食べる」という文に現れるなら確かに簡単ですが、「甘い言葉をかける」というように使われると、その意味は少し難しくなっているように感じます。このように、単語の難しさは文脈によって変わってくるのです。
深層学習
田屋さんは、このふたつの問題を深層学習を使って同時に解くことを考えました。深層学習というのは人工知能の分野で盛んに研究されている手法で、大量のデータをコンピュータに学習させることでいろいろな判断をできるようにするものです。深層学習は大雑把には次のようになっています。
まず、人間の脳の神経細胞を模した簡単な素子、ニューロンを何層にも重ね合わせたものを作ります。初期状態では、各ニューロンは何の知識も持っていないただの素子です。これは、生まれたての赤ちゃんの脳の様子に近いと考えることができます。そのような真っ白のニューロンに対して、大量のデータを与えて、各ニューロンの状態を少しずつ変化させ、与えたデータを正しく理解できるようにしていきます。これは、いろいろな経験を積むことで人が少しずついろいろなことをできるようになっていく様子に近いと考えることができます。
この手法を使えば、単語の難しさを判定する問題も解けるようになるのではないでしょうか。ひとつ目の問題、つまり大量の単語に難しさの指標を割り振るには、あらかじめ大量の単語とその難しさを用意しておき、それをニューロンに学習させておきます。これには大量の単語とその難しさの例が必要ですが、それは、適切な長い文をたくさん用意しておき、そこに各単語がどのくらい出てくるかで代用することにします。何度も出てくる単語は比較的簡単で、ほとんど出てこない単語は難しいだろうということです。これがうまくいけば、単語の難しさを判定するニューロンが得られそうです。
もうひとつの問題、つまり単語の難しさが文脈によって変化する問題については、単に単語の難しさのみを学習するのではなく、文脈と単語を合わせて学習することで対応します。つまり、同じ「甘い」という単語であっても「甘いお菓子を食べる」の「甘い」は簡単、「甘い言葉をかける」の「甘い」は難しいと学習させるのです。SemEval 2021 のコンテスト問題には、そのような文例が多数、示されていますので、それを学習させれば文脈の中での単語の難しさを判定できそうです。
このように深層学習は強力で、いろいろなところで使うことができます。しかし、単に深層学習を使いさえすればどのような問題でも簡単に解けるというわけではありません。良い結果を得るためには、さまざまな工夫が必要となります。そこが田屋さんの研究の面白いところです。今回、より良い結果を得るために、田屋さんは以下の工夫を行いました。
既存の技術の利用
最初は、既存の技術の利用です。そもそも単語の難しさを判定するためには、その前提として各単語の意味といった基本的な事柄をコンピュータが理解していないと話になりません。これらのお膳立てが整って初めて「単語の難しさ」の議論をできるようになります。ですが、このような基本的な部分を毎回、ゼロから作り上げていくのは大変です。
幸いなことに、自然言語処理の分野ではすでに多くの単語の意味を学習したニューロンが用意されています。つまり、何も知らない赤ちゃんの状態のニューロンを使うのではなく、ある程度の教育を受けた人の状態に対応するニューロンを使うことができるのです。これを使うことによって、基本的な部分の作成に時間をとられることなく、すぐに「単語の難しさ」の問題に取り掛かることができます。
問題特有の知識の導入
次に行ったのは「単語の難しさ」に特化した知識の導入です。既存の技術で作られているニューロンは、単語の意味を知っているなどある程度の教育を受けたものになっていますが、「単語の難しさ」についての教育は受けていません。そのため、これをそのまま使ったのでは「単語の難しさ」を上手に判定することはできません。そこで、既存のニューロンに対して、「単語の難しさ」に関する知識を学習させます。
ここまで行うと「単語の難しさ」を判定する準備が整います。このままでも「単語の難しさ」をある程度、判定できるようになりますが、その精度は貧弱です。これをどこまで高められるかが勝負の鍵になります。それには数々の細かな調整が必要なのですが、ここでは効果のあったふたつの重要な方法を紹介します。
敵対的学習の利用
判定の精度を高める鍵となったのが敵対的学習の利用です。一般に、深層学習によって作られたニューロンには、入力のちょっとした差異が結果に大きな影響を及ぼすことがあるという欠点があります。例えば、画像認識をするニューロンを考えてみましょう。いろいろな画像を入力して学習すると、与えられた画像が何の画像かを判定できるようになっていきます。ところが、入力の画像を少し変化させると結果が変わってしまう場合があるのです。例えば、パンダの画像を正しくパンダだと判定できていたとします。その画像に、人間にはわからないくらいのノイズを加えると、突然、判定がテナガザルになってしまったりすることがあるのです。このように、もとの入力をほんの少しだけ変更して判定結果を別のものに変えてしまうことを敵対的攻撃と呼びます。
入力のわずかな差が結果に影響を及ぼしてしまうのは好ましいことではありません。そこで敵対的学習を導入します。敵対的学習というのは、入力に人為的にわずかなノイズを与えて、それも同じ判定結果になるように学習させることです。「単語の難しさ」の場合、各単語の意味は多次元のベクトルで表されています。それをほんのわずか変化させた入力を用意し、それも同じ判定結果になるように学習させます。これを行うと、入力の変化に対して結果が安定するようになり、その結果、判定の精度を大きく向上することができました。
合議制の使用
敵対的学習以外にも細かな改良手法はいろいろ考えられます。しかし、それらの手法をどのように組み合わせたら良いのかは明らかではありません。そこで、田屋さんはこれらの手法の中から有力なものを選択して、それらを並行して試し、それぞれから得られた「単語の難しさ」の平均値を取るようにしました。良い手法の間の合議制にしたということです。
この手法を使うと、極端に簡単(あるいは難しい)とされる単語が現れにくくなる傾向にあります。複数の値の平均値を取っているため、平均値が極端な値をとるためには、合議している全員が極端な値をとらなくてはならなくなるためです。しかし、合議制を採用することで概して判定の精度は上がっていくことがわかりました。
コンテスト結果
「単語の難しさ」の問題に挑戦したのは 54 チームです。各チームは、ニューロンの学習に使用できるデータとして 7000 以上の「単語の難しさ」の例と、テスト問題として 1000 個程度の入力が与えられます。これらを使って、テスト問題に現れる単語の難しさを予測して提出します。提出された結果は、正解との間の相関係数や平均絶対誤差などの指標で評価されますが、最終的な順位は相関係数の順位で決められます。その結果、田屋さんのチームは 7 位でした。
7 位というのは悪い結果ではありませんが、田屋さんはこの結果には少し不満を持っています。というのは、田屋さんが提出した予測は、確かに相関係数は7 位でしたが、平均絶対誤差を見ると 2 位だったからです。
相関係数というのは、ふたつのデータの間に似たような傾向があるかを調べる指標で 0 から 1 の間の値をとります。例えば、算数の成績の良い人は理科の成績も良いといった傾向を調べるために使われます。「単語の難しさ」の場合では、難しいと予測された単語は正解データでも難しい傾向があるかを表現しています。このように書くと、確かに相関係数が高ければ予測は正解に近そうな印象を受けます。しかし、このような値は注意して解釈する必要があります。
図 1 は、単語の難しさの予測値と正解値を散布図にしたものの例です。ひとつひとつの点が具体的な問題に対する予測値(横軸)と正解値(縦軸)を示しています。この点が中央の点線に近ければ近いほど正解値に近い値を予測することができたことを示しています。
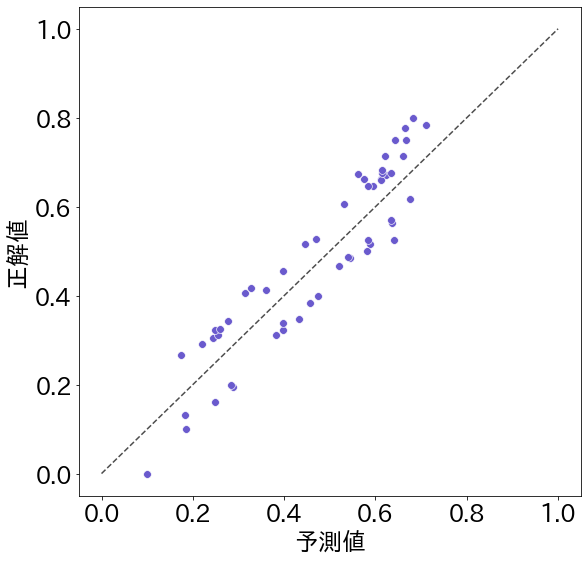
図1は相関係数が 0.93 という高い値を示しています。これは、全体の傾向として予測値が大きければ正解値も大きいという傾向がある(点が左下から右上に向かって分布している)ことを示しています。ですが、よく見ると各点は点線の上には乗っておらず、点線からはかなりずれていることがわかります。
一方、図2は田屋さんが予測した結果の散布図です。相関係数は 0.91 となっていて図1よりは低い値になっています。これは、例えば図2の一番下の点を見てみると、正解値はほぼ 0(=とても簡単な単語)であるのに対して、予測値は 0.2 程度(=比較的簡単な単語だけど「とても」簡単とまでは言えない単語)になっていて、図1ほど正解値と予測値が同じ傾向にはなってはいないと判定されたからです。
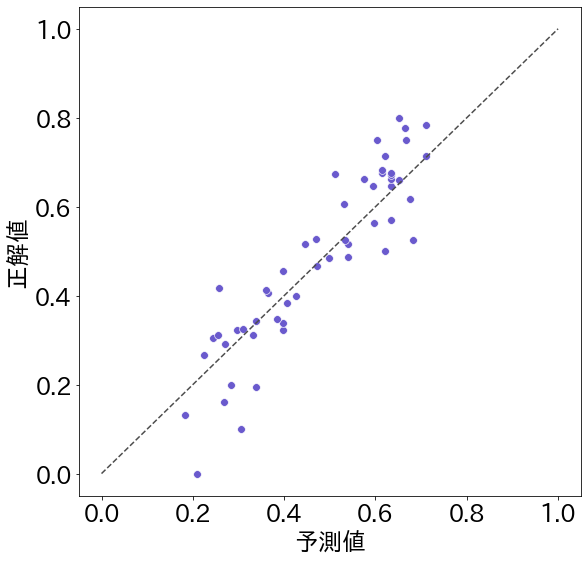
でも、図2を見ると、多くの点が点線の上、あるいはそのすぐ近くに来ていることがわかります。つまり、点線からの誤差は少なくなっているのです。そこで、ふたつの散布図の平均絶対誤差を計算してみます。平均絶対誤差というのは、予測値と正解値の差を各点について求めて、その平均値をとったものです。これは、各点がどのくらい点線(正解値)からずれているかを表す指標で、小さい値を取るほどずれが少ないことを示しています。
平均絶対誤差をみると、図1は 0.073 であるのに対して、図2では 0.066 となっており、平均絶対誤差は図2の方が小さいことがわかります。つまり、図2の方が図1よりも正解値に近い値を予測しているのです。言い換えると、図1は「何となく全体の傾向は正しい(相関係数は高い)けど個々の予測値はかなりずれている(平均絶対誤差は大きい)」のに対して、田屋さんの予測値を示した図2は「極端な値を取りにくいので相関係数は低くなっているが、個々の予測値は正確なものが多い」ということです。
コンテストで公表されているのは、相関係数や平均絶対誤差などの指標だけなので、実際に成績の良かったチームの予測値の分布がどのようになっていたのかはわかりません。でも、上のふたつの図は、ひとつの指標だけで優劣を判断するのではなく、さまざまな指標を検討するのが良いということを示していそうです。今回のコンテストでは、全体の順位を決めるためにたまたま相関係数が使用されましたが、必ずしも相関係数が高い方が優れているとは限らないのではないかというのが田屋さんの意見です。
以上がコンテストの結果ですが、田屋さんにとっては、コンテストを通じて深層学習の分野の最先端の手法を実際のデータを使って試せたことが大きな収穫でした。これを通して分野の最先端を把握することができました。特に敵対的学習を深く理解できたことが大きく、これがその後、修士の研究における田屋さんのメインの研究テーマとなりました。
バックナンバー
問い合わせ先
大学へのお問合せはこちらをご覧ください〒112-8610 東京都文京区大塚2-1-1
TEL : 03-5978-5704
FAX : 03-5978-5705
責任者 : 情報科学科HP運営委員会 伊藤貴之

※このウェブサイトは情報科学科の学生によって制作されています。